特征选择概述
特征选择的几个常见问题
为什么?
(1)降低维度,选择重要的特征,避免维度灾难,降低计算成本
(2)去除不相关的冗余特征(噪声)来降低学习的难度,去除噪声的干扰,留下关键因素,提高预测精度
(3)获得更多有物理意义的,有价值的特征
不同模型有不同的特征适用类型?
(1)lr模型适用于拟合离散特征(见附录)
(2)gbdt模型适用于拟合连续数值特征
(3)一般说来,特征具有较大的方差说明蕴含较多信息,也是比较有价值的特征
特征子集的搜索:
(1)子集搜索问题。
比如逐渐添加相关特征(前向forward搜索)或逐渐去掉无关特征(后向backward搜索),还有双向搜索。
缺点是,该策略为贪心算法,本轮最优并不一定是全局最优,若不能穷举搜索,则无法避免该问题。
该子集搜索策略属于最大相关(maximum-relevance)的选择策略。
(2)特征子集评价与度量。
信息增益,交叉熵,相关性,余弦相似度等评级准则。
典型的特征选择方法
从决策树模型的特征重要性说起
决策树可以看成是前向搜索与信息熵相结合的算法,树节点的划分属性所组成的集合就是选择出来的特征子集。
决策树划分属性的依据

通过gini不纯度计算特征重要性
不管是scikit-learn还是mllib,其中的随机森林和gbdt算法都是基于决策树算法,一般的,都是使用了cart树算法,通过gini指数来计算特征的重要性的。
比如scikit-learn的sklearn.feature_selection.SelectFromModel可以实现根据特征重要性分支进行特征的转换。
mllib中集成学习算法计算特征重要性的源码
在spark 2.0之后,mllib的决策树算法都引入了计算特征重要性的方法featureImportances,而随机森林算法(RandomForestRegressionModel和RandomForestClassificationModel类)和gbdt算法(GBTClassificationModel和GBTRegressionModel类)均利用决策树算法中计算特征不纯度和特征重要性的方法来得到所使用模型的特征重要性。
而这些集成方法的实现类都集成了TreeEnsembleModel[M <: DecisionTreeModel]这个特质(trait),即featureImportances是在该特质中实现的。
featureImportances方法的基本计算思路是:针对每一棵决策树而言,特征j的重要性指标为所有通过特征j进行划分的树结点的增益的和
将一棵树的特征重要性归一化到1
将集成模型的特征重要性向量归一化到1
皮尔森相关系数(Pearson Correlation Coefficient)
$$
\rho_{X,Y} = \frac{cov(X,Y)}{\sigma_X\sigma_Y} = \frac{E(XY)-E(X)E(Y)}{\sqrt{E(X^2)-E(X)^2}\sqrt{E(Y^2)-E(Y)^2}}
$$
最大相关最小冗余(mRMR)算法
互信息
互信息可以看成是一个随机变量中包含的关于另一个随机变量的信息量,或者说是一个随机变量由于已知另一个随机变量而减少的不确定性。互信息本来是信息论中的一个概念,用于表示信息之间的关系, 是两个随机变量统计相关性的测度。

mRMR
之所以出现mRMR算法来进行特征选择,主要是为了解决通过最大化特征与目标变量的相关关系度量得到的最好的m个特征,并不一定会得到最好的预测精度的问题。
前面介绍的评价特征的方法基本都是基于是否与目标变量具有强相关性的特征,但是这些特征里还可能包含一些冗余特征(比如目标变量是立方体体积,特征为底面的长度、底面的宽度、底面的面积,其实底面的面积可以由长与宽得到,所以可被认为是一种冗余信息),mRMR算法就是用来在保证最大相关性的同时,又去除了冗余特征的方法,相当于得到了一组“最纯净”的特征子集(特征之间差异很大,而同目标变量的相关性也很大)。
作为一个特例,变量之间的相关性(correlation)可以用统计学的依赖关系(dependency)来替代,而互信息(mutual information)是一种评价该依赖关系的度量方法。
mRMR可认为是最大化特征子集的联合分布与目标变量之间依赖关系的一种近似。
mRMR本身还是属于filter型特征选择方法。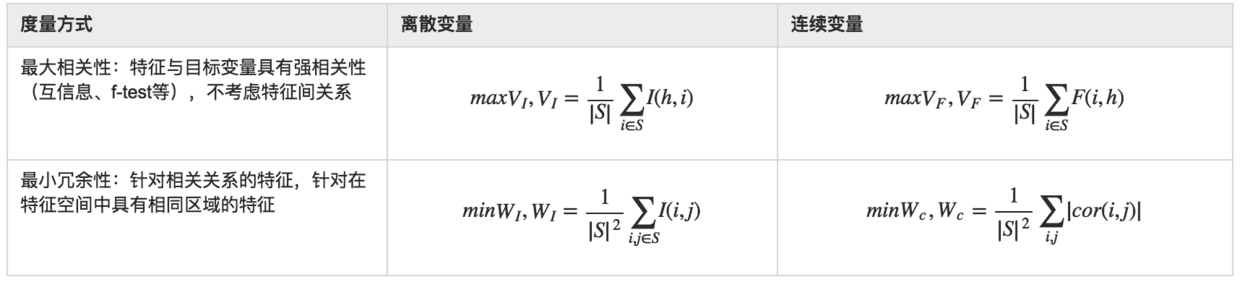
可以通过max(V-W)或max(V/W)来统筹考虑相关性和冗余性,作为特征评价的标准。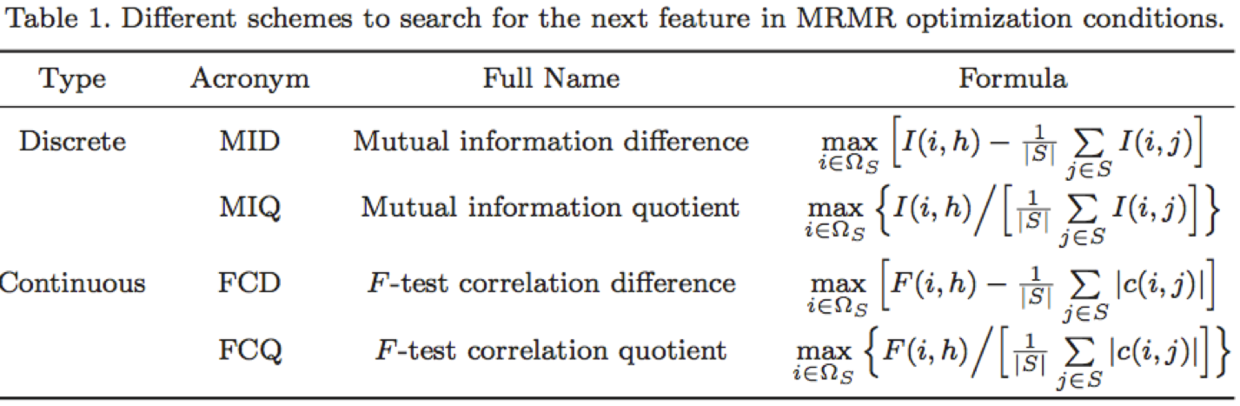
附录
逻辑回归模型与离散特征
将连续特征离散化(像是独热编码之类的技巧)交给逻辑回归模型,这样做的优势有以下几点:
- 稀疏向量内积乘法运算速度快,计算结果方便存储,容易扩展。
- 离散化后的特征对异常数据有很强的鲁棒性:比如一个特征是年龄>30是1,否则0。如果特征没有离散化,一个异常数据“年龄300岁”会给模型造成很大的干扰。
- 逻辑回归属于广义线性模型,表达能力受限;单变量离散化为N个后,每个变量有单独的权重,相当于为模型引入了非线性,能够提升模型表达能力,加大拟合。
- 离散化后可以进行特征交叉,由M+N个变量变为M*N个变量,进一步引入非线性,提升表达能力。
- 特征离散化后,模型会更稳定,比如如果对用户年龄离散化,20-30作为一个区间,不会因为一个用户年龄长了一岁就变成一个完全不同的人。当然处于区间相邻处的样本会刚好相反,所以怎么划分区间是门学问。
李沐少帅指出,模型是使用离散特征还是连续特征,其实是一个“海量离散特征+简单模型” 同 “少量连续特征+复杂模型”的权衡。既可以离散化用线性模型,也可以用连续特征加深度学习。
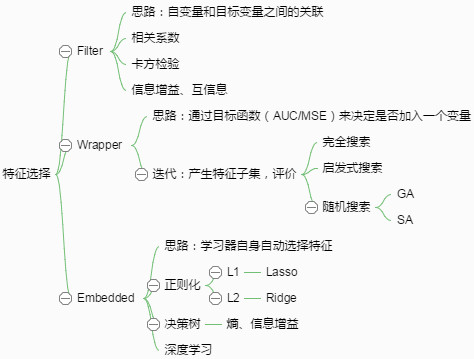
特征选择
当数据预处理完成后,我们需要选择有意义的特征输入机器学习的算法和模型进行训练。通常来说,从两个方面考虑来选择特征:
- 特征是否发散:如果一个特征不发散,例如方差接近于0,也就是说样本在这个特征上基本上没有差异,这个特征对于样本的区分并没有什么用。
- 特征与目标的相关性:这点比较显见,与目标相关性高的特征,应当优选选择。除方差法外,本文介绍的其他方法均从相关性考虑。
根据特征选择的形式又可以将特征选择方法分为3种:
- Filter:过滤法,按照发散性或者相关性对各个特征进行评分,设定阈值或者待选择阈值的个数,选择特征。
- Wrapper:包装法,根据目标函数(通常是预测效果评分),每次选择若干特征,或者排除若干特征。
- Embedded:嵌入法,先使用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据系数从大到小选择特征。类似于Filter方法,但是是通过训练来确定特征的优劣。
我们使用sklearn中的feature_selection库来进行特征选择。
Filter
方差选择法
使用方差选择法,先要计算各个特征的方差,然后根据阈值,选择方差大于阈值的特征。使用feature_selection库的VarianceThreshold类来选择特征的代码如下:
相关系数法
使用相关系数法,先要计算各个特征对目标值的相关系数以及相关系数的P值。用feature_selection库的SelectKBest类结合相关系数来选择特征的代码如下:
卡方检验
经典的卡方检验是检验定性自变量对定性因变量的相关性。假设自变量有N种取值,因变量有M种取值,考虑自变量等于i且因变量等于j的样本频数的观察值与期望的差距,构建统计量:
$$
\chi^2 = \sum{\frac{(A - E)^2}{E}}
$$
不难发现,这个统计量的含义简而言之就是自变量对因变量的相关性。用feature_selection库的SelectKBest类结合卡方检验来选择特征的代码如下:
互信息法
经典的互信息也是评价定性自变量对定性因变量的相关性的,互信息计算公式如下:
$$
I(X;Y)=\sum_{x\in X}\sum_{y\in Y} p(x,y)\log {\frac{p(x,y)}{p(x)p(y)}}
$$
为了处理定量数据,最大信息系数法被提出,使用feature_selection库的SelectKBest类结合最大信息系数法来选择特征的代码如下:
Wrapper
递归特征消除法
递归消除特征法使用一个基模型来进行多轮训练,每轮训练后,消除若干权值系数的特征,再基于新的特征集进行下一轮训练。使用feature_selection库的RFE类来选择特征的代码如下:
Embedded
基于惩罚项的特征选择法
使用带惩罚项的基模型,除了筛选出特征外,同时也进行了降维。使用feature_selection库的SelectFromModel类结合带L1惩罚项的逻辑回归模型,来选择特征的代码如下:
实际上,L1惩罚项降维的原理在于保留多个对目标值具有同等相关性的特征中的一个,所以没选到的特征不代表不重要。故,可结合L2惩罚项来优化。具体操作为:若一个特征在L1中的权值为1,选择在L2中权值差别不大且在L1中权值为0的特征构成同类集合,将这一集合中的特征平分L1中的权值,故需要构建一个新的逻辑回归模型:
使用feature_selection库的SelectFromModel类结合带L1以及L2惩罚项的逻辑回归模型,来选择特征的代码如下:
基于树模型的特征选择法
树模型中GBDT也可用来作为基模型进行特征选择,使用feature_selection库的SelectFromModel类结合GBDT模型,来选择特征的代码如下: